QWER.GG 를 통해 배운 것들

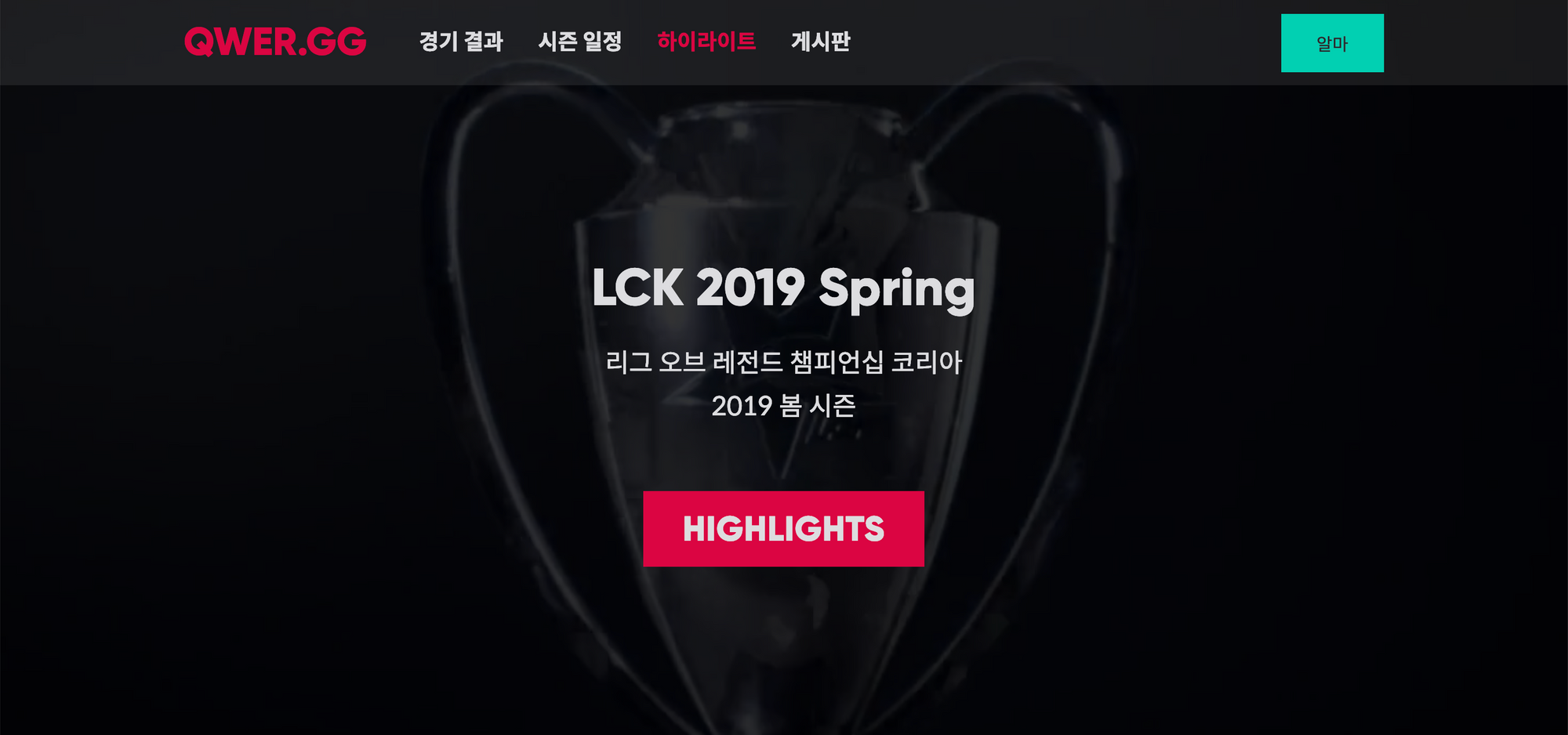
요즘 시간 날때마다 QWER.GG 라는 웹서비스를 사이드 프로젝트로 개발 및 운영하고 있다. 덕심으로 시작해 근성으로 계속하고 있는데, 2달만에 꽤 의미있는 수준으로 발전한 것 같아서 일종의 포스트모템 을 나눠보고자 한다.
홍보타임
아래의 내용은 QWER.GG 홍보를 포함하고 있으니 불편하신 분은 다음 섹션으로 내려주시면 됩니다.
QWER.GG 는 E-Sports 특히 League of Legends Korea Championship (이하 LCK) 경기를 찾아보고 팀 혹은 선수를 덕질하기 위해 만든 사이트로 경기 일정, 랭킹, 게시판 등을 서비스하고 있다.

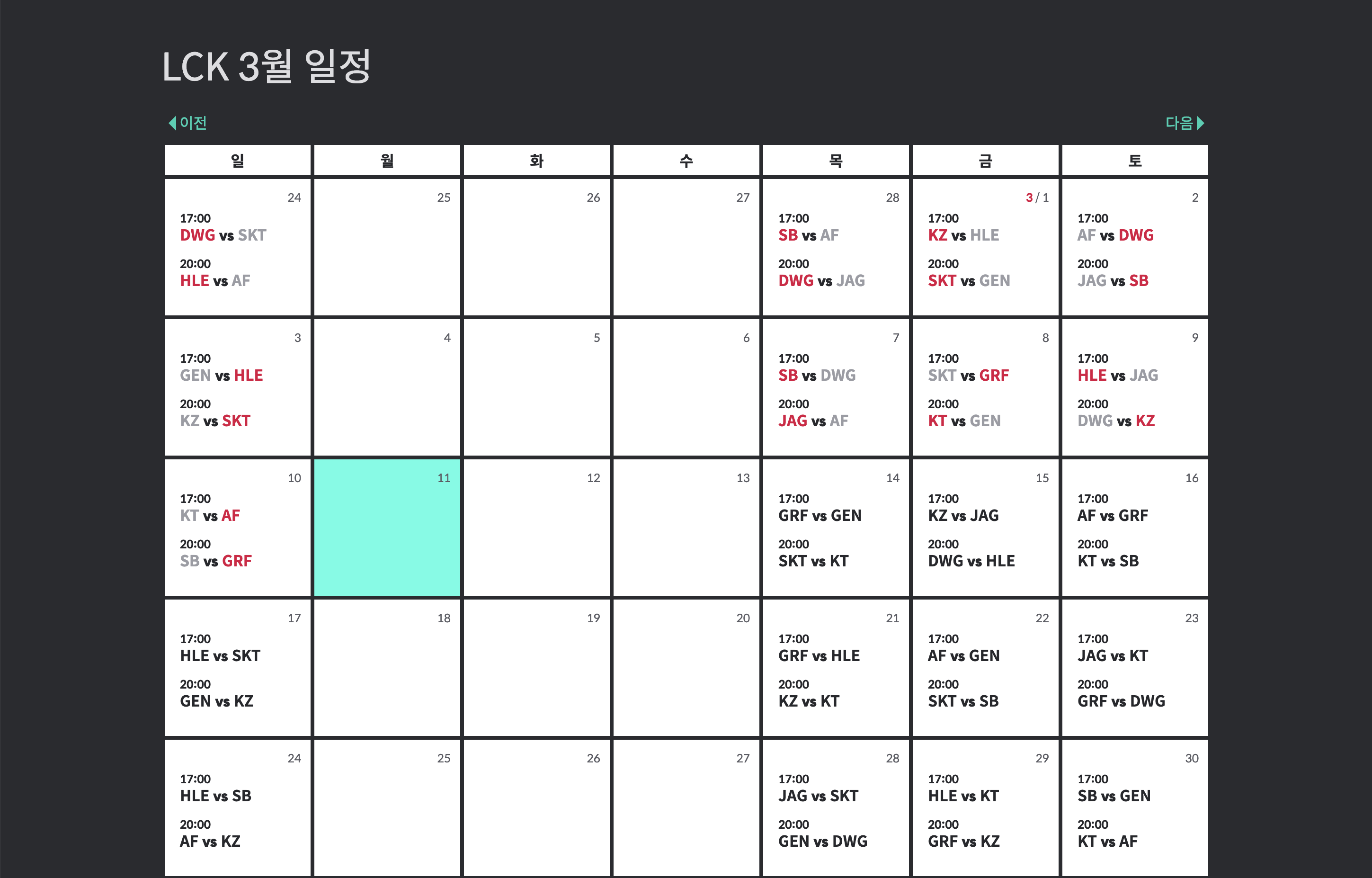
경기 결과나 전체 혹은 분석 영상 등도 업로드 하고 있으니 관심있으면, QWER.GG 로 접속해보시기를!

0. Architecture
소프트웨어 엔지니어링에서 아키텍처는 과대평가 되어 있고, 디자인 패턴은 과소평가 되어 있다. 그리고 코딩은 아예 평가 조차 되고 있지 않다.
- 김석준
위의 Quote(?) 에 대해서는 다시한번 이야기할 기회가 있을거 같아서 이번엔 일단 패스한다. 어쨋든 QWER.GG 는 MST 를 지향하되 단순함을 지키고자 한다.
QWER.GG Backend
QWER.GG 의 백엔드는 기본적으로 TypeScript, Node.js, Express 그리고 MongoDB 로 구성되어 있다.
- 원래는 Elixir 를 공부하는 샘 치고 백엔드 메인으로 가져가려고 했는데
1)MongoDB 쪽 업댑터가 부실하고,2)concurrency 이슈가 발생할 일이 상대적으로 거의 없을것 같다는 생각,3)사이드 프로젝트로 서비스 개발하는데 러닝 커브도 우려되어 익숙한 Node.js 와 Express 를 선택했다. - MongoDB 의 경우는 크게 고민하지 않고 선택하였다. 사이드 프로젝트 특성상 느긋하게 단단한 설계를 하기 보다는 여가 시간을 활용해야 하는 만큼 그때 그때 수정사항이 발생하고, 이후에 추가해야하는 게임 데이터들은 크롤링에 의존해야 하기 때문에 역시 미리 스키마를 정해놓기 어려웠다. 또한 데이터의 정합성을 중요시하기보다 어떻게든 적재하고 나서 필요하면 migration 하는 방향을 선택했기 때문에 MySQL 과 같은 관계형 DB 와 매우 안어울리는 개발 방향이라고 할 수 있겠다.
덕분에 한번쓰고 버려지는 migration 코드가 매우 많아졌다 - 개인 프로젝트라도 서비스를 하게 되면 금전적인 부담을 무시할 수 없어서 캐시와 큐를 위해 redis, rabbitmq 같은 기술을 도입하기 보다는 메모리 와 node-cron 패키지 사용했다. api 리퀘스트 부담을 줄이기 위해 apicache 라는 패키지를 사용해보았는데 생각보다 효율이 좋지 못해 삭제를 고민중이다. 뒤에 다시 한번 언급하겠다.
- 데이터 크롤링에는 cheerio 를 사용했고, 특성상 한땀한땀
고이접어 나빌래라코딩하였다.
QWER.GG Frontend
프론트엔드 라이브러리의 제왕, React 를 기본으로 역시 Typescript 를 적용하였다. CSS Framework 은 그다지 선호하지 않으나, 컴포넌트 제작에 대한 부담을 줄이려 bootstrap 을 적당히 커스터마이징 해서 사용하고 있고, 에러 리포터는 Sentry 를 적용했다. 이 역시 뒤에 다시 한번 언급하겠다.
- React 는 손에 가장 잘 맞기도 하고 워낙 많이 써봐서 고민 없이 선택했다. Vue.js vs React 뭐 이런 글들이 많이 돌아다니는데 그저 취향 정도 차이라고 생각한다. 딱히 Vue.js 가 React 에 비해서 생산성이 월등하지도 않고 고민할 거리도 아니었다. 다만 Server Side Rendering 은 필요하지만 뒤로 밀어뒀는데, CRA v2 TS 로 세팅하는게 익숙치 않아서 어쩔 수 없이 Client Side Rendering 만을 현재 지원하고 있다.
그냥 boilerplate 가져다 쓸걸... - RxJS 를 적극적으로 써보려고 있다. redux 에 redux-observable 로 비동기 처리를 하는 것도 그렇지만, rx.js 로 해결되는 문제를
적극적으로으로 찾고 있다는 의미이다. 예를 들어 SPA 에서는 화면 전환 코스트가 거의 없다보니 불필요한 API Request 에 대한 처리가 눈에 안보이는 곳에서 이루어지기 마련이다. QWER.GG 게시판 에 적용하여 게시판을 반복적으로 전환할때 필요없는 reponse handler 를 cancel 하도록 rx.switchMap 을 적용했다. - 비지니스 로직이 그다지 중요하지 않아서 과감하게 map 파일까지 serving 하도록 했다. sentry 에 따로 올려둬서 resolve 시킬 수 있지만
패기로번거로움을 피하였다.
1. Size DOES Matter
아무래도 프론트엔드 개발을 주로 하다보니 상대적으로 데이터 파싱, 렌더링 중복 같은 브라우저측 최적화에는 신경을 많이 쓰는데, 백엔드에서 데이터 사이즈를 최적화 해야겠다는 생각은 못했었다.
QWER.GG 는 현재 매치 일정은 수동으로 입력하고, 각 게임의 결과는 크롤링을 데이터를 만들어주고 있다. 게임의 상세 데이터와 타임라인까지 전부 game collection 안에 넣다 보니 하나의 game document 가 JSON 기준으로 15,000 줄에 에 가까운 크기를 가지게 되었다. 이정도 사이즈일거라고 당연히 생각하지 못했고 nginx 에서 504 Gateway Timeout 이 계속 발생하여 확인해 보았더니 이런 현상이 발생하고 있었다.
계산을 해보자.
LCK 2019 Spring 시즌에는 약 150개 이상가는 match 가 있다. 이 각 match 는 2-3 개의 game 가 존재하고 편의를 위해 특정 api 에서는 모든 match 를 가져오게 개발되어 있다. 150 * (2 * 15,000) 이면 4,500,000 이고 한줄에 5글자씩만 있다고 가정해도 이는 약 (4,500,000 / 1,000 / 1,000) * 5 = 22.5 무려 20메가를 넘어가게 된다. (실제로는 당연히 이보다 컸다) API 의 반응 속도에만 집중하다보니 데이터의 양적인 부분에서 문제가 발생할 가능성을 간과하였고, MongoDB 의 아무렇게나 때려넣어도 잘됨 과 합쳐지다보니 부작용이 발생하였다. crawler 구조를 수정하고 migration 을 진행하였다. json 이라고 얕보지 말자
2. Cache should be done RIGHT
Express 는 미들웨어를 통해서 간단하게 api response 를 캐싱할 수 있다. 직접 만들수도 있지만 apicache 패키지와 같은 패키지를 사용하면 되는데, 코드 를 보면 아래와 cache key 로 url 을 기본으로 캐싱하여 메모리에 response 를 캐싱하고 있다.
var key = req.originalUrl || req.url
이는 일정 기간동안 response 를 캐싱하고 있다가 리턴해주고, 기간이 초과되면 정상적으로 middleware 의 next() 를 통해 response 를 새로 리턴하고 캐싱하는 방식으로 매우 직관적이다. 문제는, 일정 기간 캐싱하고 있다가 새로 리턴하는 방식 때문에 일어난다. 결국 지정 기간 동안에는 속도가 빠르지만 처음 캐시가 생성되는 request 동안에는 실제로 다시한번 데이터를 만들기 때문에 일시적으로 속도가 캐싱 안된 속도로 떨어지게 된다.
물론 이는 큰 문제가 안되고 당연한 이야기일수 있지만, 그 작업이 매우 느릴 경우에는 에로사항이 꽃핀다. 그도 그럴것이 모든 match 와 game 결과를 다 확인해야 하는 team, mvp rank 알고리즘의 속도가 느리기 때문에 이러한 방식의 캐싱은 결코 효과적이라 할 수 없다. 물론 코드의 퍼포먼스를 개선할 필요도 있다고 생각할 수 있지만, 실시간 데이터로 리턴해야 할 필요성이 매우 낮기 때문에 굳이 개선하기 보다는 스케쥴러를 통해서 미리 만들어놓는 것이 훨씬 더 효과적이다.
let ranks = [];
(async () => {
ranks = await getRanks();
setInterval(async () => {
ranks = await getRanks({});
}, A_MINUTE * 3);
})();
router.get('/ranks', async (req, res) => {
if (ranks.length === 0) {
ranks = await getRanks();
}
res.json(ranks);
});
위와 같은 방식으로 간단한 방법으로 퍼포먼스 개선 효과를 크게 얻을 수 있었다. 사실 조금 더 시간을 투자할 수 있다면, 이런 방식 말고도 실제로 ranks 에 변화를 주는 데이터가 있을 경우에만 캐시를 업데이트 해줄 수도 있겠지만, 귀찮아서 안했지 캐시에 영향을 주는 코딩은 가급적이면 단순하게 눈에 보이는 방식으로 처리를 하는 편이 좋다고 생각하다. 캐시 인벨리데이션은 IT 서비스 개발분야의 짜증유발자 중 하나이기 때문에.
3. Single Page Application 에서의 로그인 처리
SPA 에서 로그인 처리는 검색해보면 주로 JWT 와 같은 웹토큰을 브라우저에 저장하고, query param 이나 header.authorization 에 bearer token 형태로 주입하는 방식을 주로 권하는 글들이 많다. 혹은 급진주의자들은 JWT 를 채용하여 browser 에 어느정도 처리를 일임하기도 한다. 전통적으로 로그인 처리는 cookie 를 이용한 server side 에서 session 에서 담당하는 경우가 많은데 SPA 서도 충분히 그러한 것이 가능하다. (제약사항이 생기긴 하지만)
몇가지 알아야 할 점은 SPA 는 일반적으로 browser 에서 최초의 index.html 에 대한 GET request 를 제외하고 (즉, 브라우저에서 주소를 입력하고 엔터를 눌렀을 때 이후로는) 페이지 이동시에 새로운 페이지에 대한 request 를 보내지 않고 History API 를 사용하여 주소창의 uri 를 변경한 후, 변경된 uri 에 대한 화면을 그린다. (모던 브라우저 한정) 때문에 실제로 서버에서 로그를 찍어보면 변경된 주소창의 uri 에 대한 요청이 들어오지 않는 것을 알 수 있다. 이 말은 반대로 생각하면 History API 를 통하지 않는다면 일반적이 서버 사이드 cookie 를 사용할 수 있다는 의미기도 하다.
Fetch API 는 headerless 라고 착각하기 쉽지만, header 를 포함하는 옵션인 credentials 의 기본 값이 same-origin 로 cookie 를 함께 보내게 된다.
(기본값이 omit 에서 same-origin 으로 변경되었다. 물론 same-origin 이 아니어도 include 로 포함시켜줄 수 있다.) 다만 fetch 는 cookie 를 set 해줄 수는 없기 때문에 직접 browser 가 서버에 다녀와야 한다. QWER.GG 는 프론트엔드 에서 <a> 태그를 직접 사용하여 서버쪽으로 직접 request 를 보내주었고, 현재 facebook 로그인만을 지원하기 때문에 callback 을 받아 cookie 를 지정해주고 다시 프론트엔드로 redirect 해주는 방식을 사용하고 있다. 물론 페이스북 뿐만 아니라 다른 oAuth 도 유사한 방식으로 동작하기 때문에 그대로 사용할 수 있고, 직접 로그인 기능을 구현한다면 form.submit 의 html 기본 동작을 활용하도록 하자.
이렇게 로그인 처리를 하면 서버에서 session 관리하기 용이하고, JWT 로 로그인을 처리할때 번거로운 강제 로그아웃도 쉽게 할 수 있다. 프론트엔드에서의 로그아웃의 경우 쿠키를 지워주거나 역시 request 를 서버에 보내는 방식으로 처리한다.
4. API Request
Single Page Application 경우 주로 static website hosting 을 이용하는데 당연히 귀찮아서 CRA v2 에서 권장하는 방식으로 간단하게 배포하고 있다.
$ npm run build
...
The build folder is ready to be deployed.
You may serve it with a static server:
npm install -g serve
serve -s build
Find out more about deployment here:
http://bit.ly/CRA-deployMSA 를 지향한다고는 하지만 역시 비용적인 면이 부담스럽고, Google Cloud 의 라우팅 설정이 아직 익숙치 않아서 서버 하나에 NGINX 를 앞에 두고 API 서버와 프론트엔드 static web server 로 reverse proxy 설정을 통해 서빙하고 있다.
http {
...
upstream qwer.gg-back {
server back:4000;
}
upstream qwer.gg-front {
server front:3000;
}
server {
server_name qwer.gg;
server_name www.qwer.gg;
location /api/ {
include /etc/nginx/reverse-proxy.conf;
proxy_pass http://qwer.gg-back/;
}
location / {
include /etc/nginx/reverse-proxy.conf;
proxy_pass http://qwer.gg-front;
}
}
}디테일한 설정은 생략했지만, 대략 이런식으로 구성하여 gate, qwer.gg-back, qwer.gg-front 3개의 Docker Instance 가 각각의 역할을 다하고 있다. static 에셋의 경우 nginx 의 캐시 기능이 꽤 훌륭하여 사용자가 없는 많지 않은 지금 충분히 그 역할을 다하고 있다.
이렇게 nginx reverse-proxy 로 라우팅을 하게 되면 생기는 장점은 CORS 문제를 고민할 필요가 없다는 것이다. 상술했듯 브라우저에서 이루어지는 모든 AJAX 호출은 Same Origin 한정 Cookie 를 Header 에 함께 전송하기 때문에 전통적인(?) 서버 사이드 세션을 사용할 수 있고, 또한 Same Origin 이라 불필요한 Preflight OPTIONS request 를 피할 수 있다.
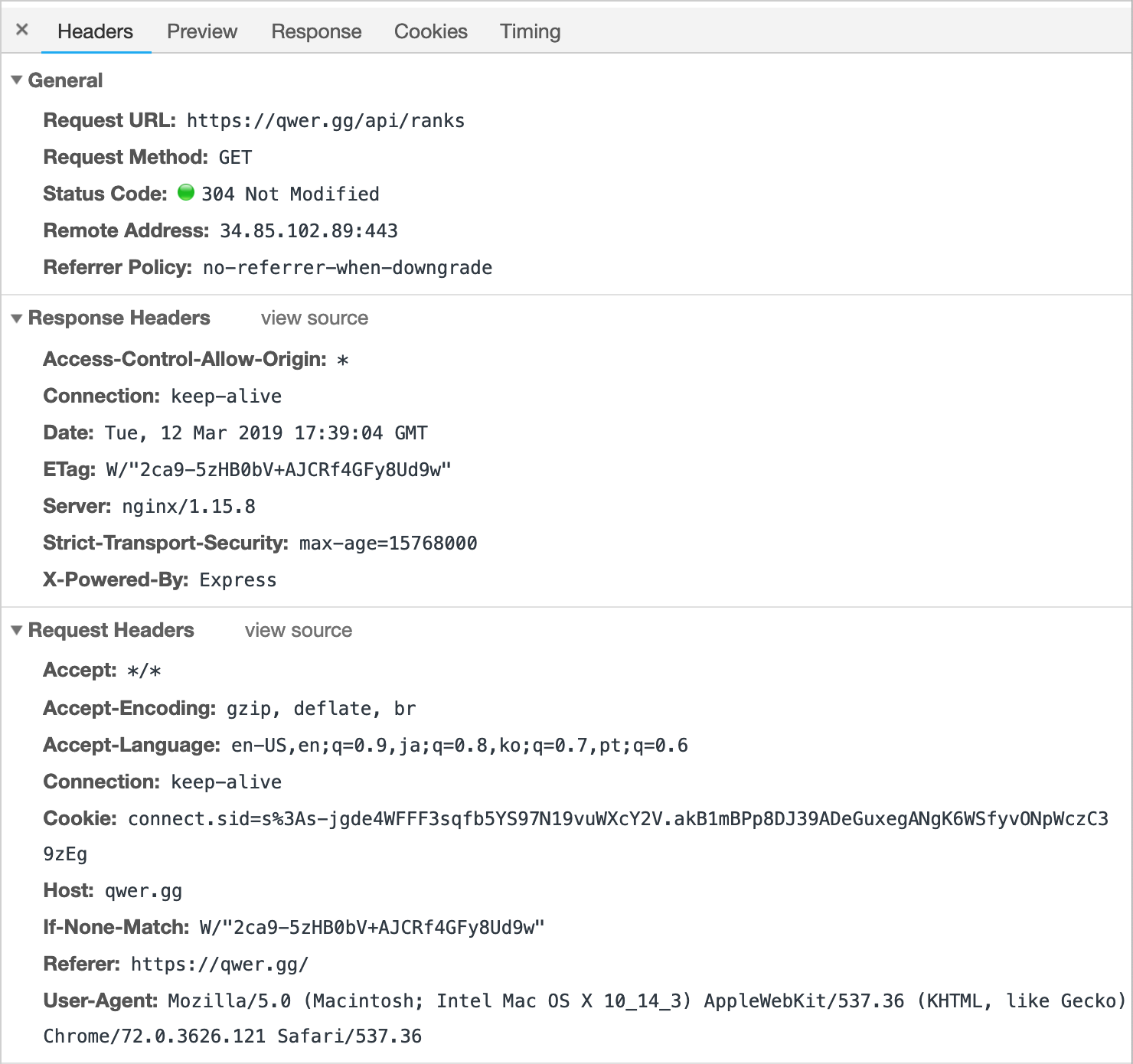
개발툴로 확인해보면 서버는 다른 포트에 열려있음에도 CORS 문제가 발생하지 않는다. CRA v1 과는 다르게 v2 는 proxy 설정 또한 setupProxy.js 를 만들어 두면 좀 더 디테일하게 설정이 가능하다.
var proxy = require('http-proxy-middleware');
module.exports = (app) => {
app.use('/api', proxy({
target: 'http://localhost:4000',
}));
app.use('/auth', proxy({
target: 'http://localhost:4000',
}));
}QWER.GG 의 설정은 위와 같다.
5. External Service Integration
CD/CI 는 Jenkins 를 통해서 진행하고 있고, 로깅은 slack 으로 대체하고 있다. 에러 리포트는 Sentry, 분석은 GA 로 흔히 많이 하는 것들을 채용했다. 쉬우니까
1) Sentry & GA
뭐 워낙 많이 쓰이는 툴이라 굳이 길게 이야기하지 않겠지만 Sentry 는 그리 어렵지 않으니 왠만하면 설정해두는 것을 추천한다. 사이드 프로젝트는 자주 들어가보지 못하기 때문에, 일을 쌓아놓고 하게 되는데 이럴 경우 에러 리포트가 큰 도움이 된다.
SPA 는 GA 스크립트만 넣어두면 URI 를 제대로 인식하지 못하기 때문에 Google Tag Manager 로 history.push 이벤트에 제대로 설정을 하도록 하자.
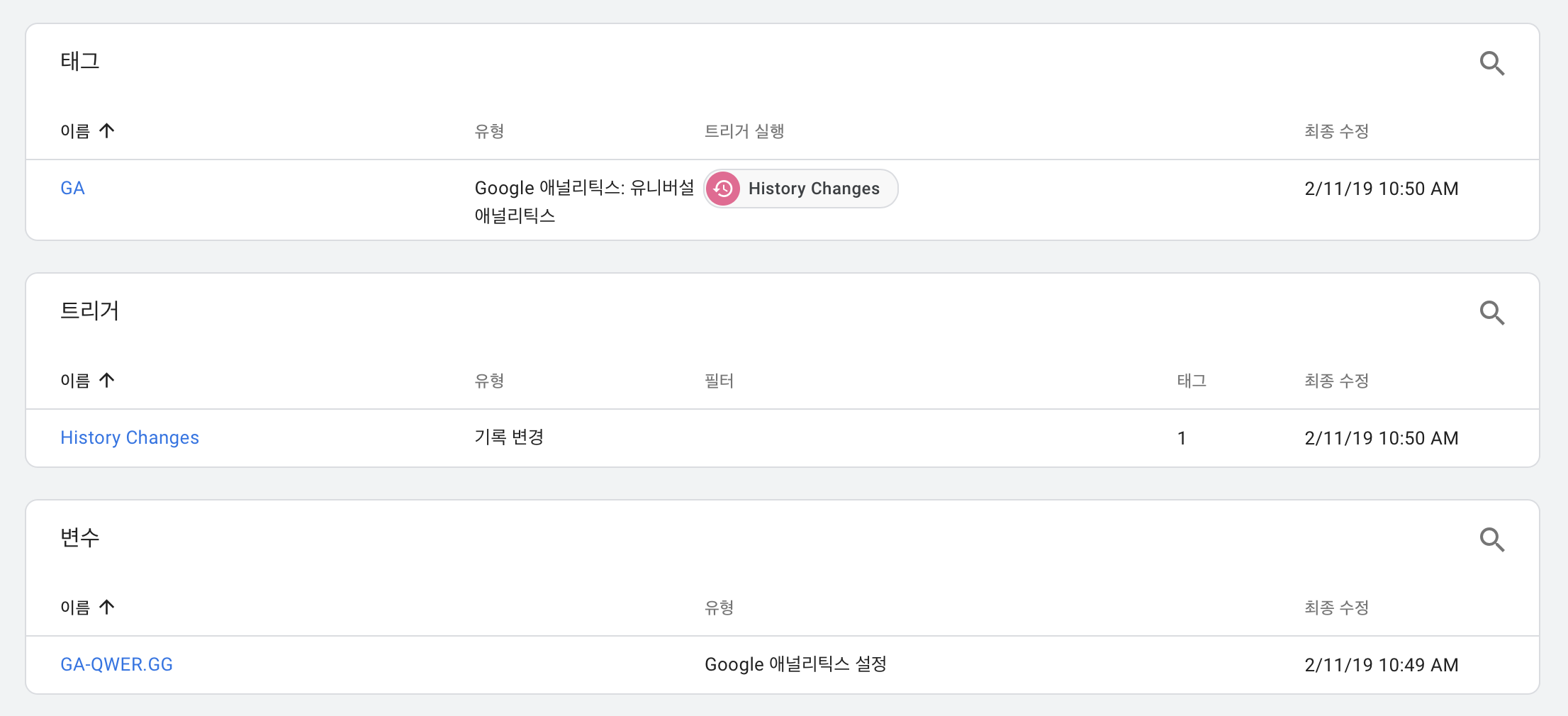
자세한 내용은 링크 를 참고하거나 검색을 해보길.
2) Jenkins
사이드 프로젝트에서도 CI/CD 는 세팅해 두는 것을 권한다. 짤봇 프로젝트의 경우에는 slack gif 슬래시 커맨드를 기본으로 이미지 쿼리를 위한 API 서버를 분리하면서 프론트를 추가시켜 MST 구조의 서비스 형태로 발전시키고 있는데, 이게 벌써 거의 3년전에 시작한 프로젝트다. 오랫동안 방치해 둔 프로젝트 였지만 최근까지 얼마 안되는 유저가 열심히 쓰고 있다는 사실을 알고 발전시키고 있는데, 과거에 세팅해둔 Jenkins 가 큰 도움이 되었다.
여기서 한가지 팁은 빌드 서버는 사양이 좋아야 되는데 개인 프로젝트에서는 오히려 실제 서버보다 큰 사이즈를 차지하기 쉽상이다. 따라서, 빌드 서버는 AWS 든 GCP 든 bitnami 같이 편한 방법으로 올려두고, 사용할때만 켜두는 것이 좋다. 그러면 높은 사양의 빌드 서버를 적은 비용으로 유지할 수 있다.
3) Slack Integration
슬랙은 정말 이제 개발자에게서 빼놓을 수 없는 툴이 된 것 같다. 웹훅 은 매우 편리하고 확장성도 좋다. 물론 Express 라면 mogran 으로 log 를 기록하고 logstash 같은 툴을 사용한다면 얼마나 좋겠냐만은, 금전적인 비용 보다도 관리 비용이 더 무시무시하다. 따라서 에러가 될만한 부분에 slack webhook 과 연동시켜 놓으면 좋다.
const logger = {
error: async (...args: any[]) => {
console.error(...args);
await notifyToSlack('error', args.join(' '));
}
}
에러가 throwing 되는 부분에 slack 과 연동되는 logger 를 만들어서 (console.prototype 에 엮을 수도 있겠지만귀찮아서) 처리해두면 에러 로그를 직접 들여다보는 수고 없이 간단하게 문제를 확인할 수 있다. error.stack 을 code-snippet 으로 만들어 로깅 하기를 추천한다.
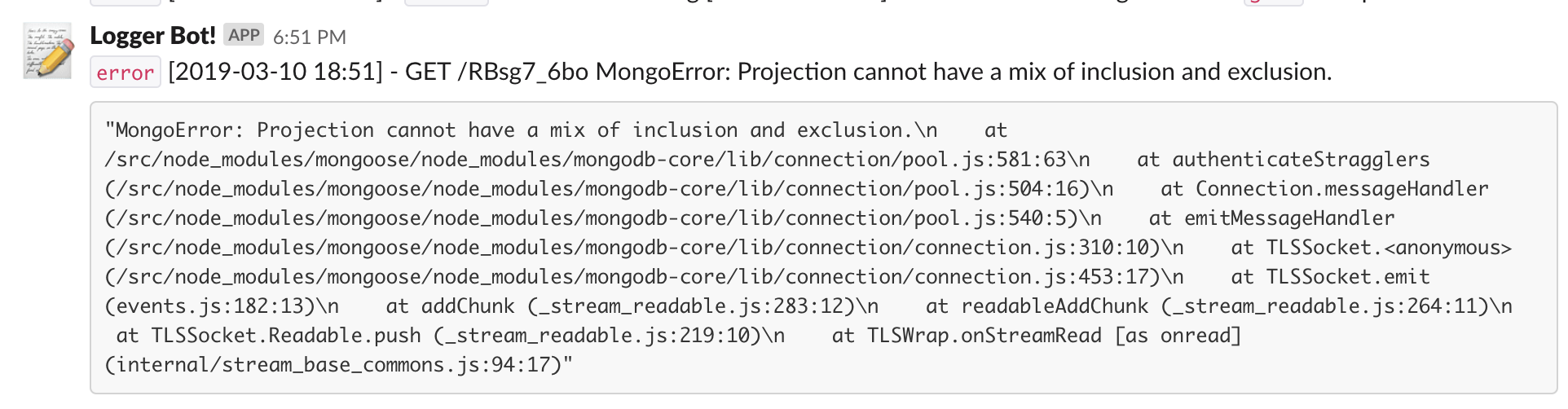
이런식으로 깔끔하게 로깅을 하는 것이 가능하다. 뭐 로그를 분석하기에 좋은 방식은 아니지만, 에러를 빠르게 캐치하는데는 이 보다 나은 방법도 드믈다.
사이드 프로젝트에 대한 오해를 하는 경우가 "시간이 생기면 해야지" 라는 부분인데, 그 때 는 장담하건데 결코 도래하지 않을 것이다. 하고 싶은게 없다면 모르겠지만, 관심이 있는 분야가 있다면 시간은을 만들어서 해보길 권장한다. 안해본 것을 통해서 배울 것도 많고, 혹시 아나 잘 되서 돈 팡팡 벌지!