한국화 안되는 고전게임 AI 로 한글화 하기
30년 전 1바이트 엔진에 2바이트 한글을 심다: 키란디아의 전설 2 리버스 엔지니어링 및 ScummVM 공식 기여기 1993년 출시된 웨스트우드의 명작 '키란디아의 전설 2'는 독자적인 바이너리 구조와 ASCII 전제 엔진 탓에 오랜 시간 한글화의 사각지대에 있었다. 본 글에서는 Python을 이용한 PAK/EMC 포맷 분석부터, AI(OpenCode)를 활용한 4,448개 문장 번역, 그리고 ScummVM 엔진의 폰트 렌더링 로직을 직접 수정하여 공식 레포지토리에 Pull Request를 보낸 기술적 여정을 상세히 공유한다.

1부. "이 게임, 한국어판이 없다"
1-1. "키란디아의 전설 2: 운명의 손"은 어떤 게임인가?
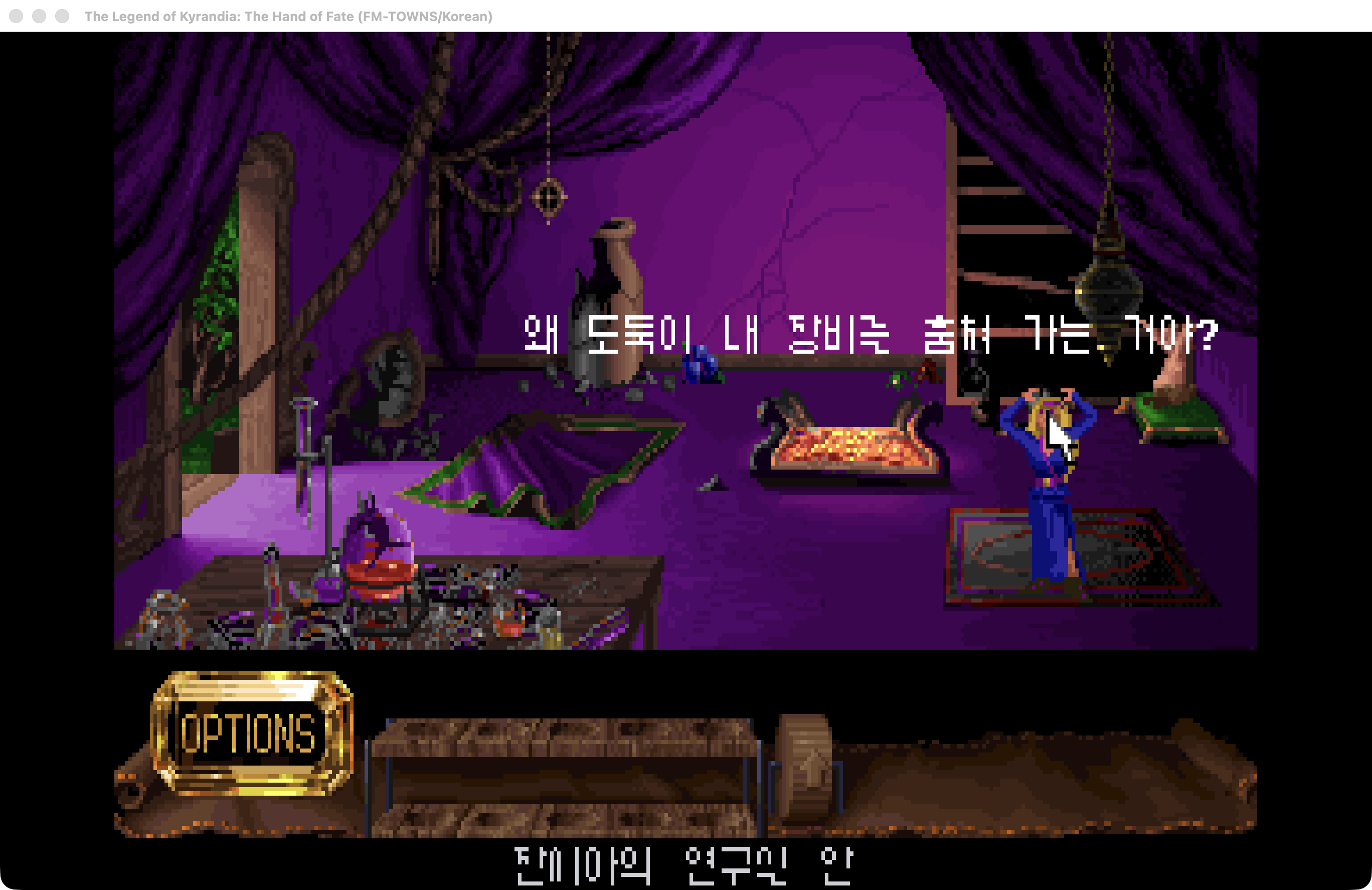
때는 1992년 포인트 앤 클릭 어드벤처 게임의 황금기였던 그 때, 나중에 커맨드 앤 퀀커 라는 불새출의 전략 게임을 만들게 되는 웨스트우드 스튜디오에서 키란디아의 전설 1편을 발매한다. 전세계적으로 흥행한 작품은 아니었지만, 한국에서는 지금은 사라진 동서게임채널을 통해 완전 한글화되어 출시되어서 인지도가 상당히 높았다.
키란디아의 전설 2 은 운명의 손 이라는 부제를 가지고는 1년 후인 1993년에 발매되었는데 1편의 절반 수준의 판매량을 기록하여서 상업적으로는 성적이 좋지 않았다. 평가가 안좋았던 키란디아의 전설3 는 그래도 정발에 한글화까지 되었지만, 2편은 정발이 안된 것으로 알고 있고, 고전 게임 팬들 사이에서는 아이러니 하게도 가장 완성도 높은 게임으로 평가되고 있지만, 한글화 되지 못한채 벌써 35년이 흘렀다.
1-2. "그냥 번역 파일 넣으면 되는 거 아니야?"
Lucas 의 SCUMM 이나 Sierra 의 SCI 의 경우는 꽤 팬 한글화 된 게임이 있는데, kyra 엔진의 경우는 그렇지 않았다. 몇 게임이 없어서 그럴지도 모르겠다. 키란디아는 ScummVM 에서 kyra 엔진을 사용하는데 1) 독자적인 파이너리 포맷 (PAK 아카이브, EMC 스크립트, DLG 대화 파일 등) 과 2) 1바이트 ASCII 전제로 짜인 엔진 덕분에 2바이트 한글(euc-kr)은 고려조차 안 되어 있었다. 3) 마땅한 폰트 조차 없었다.
[원본 게임] → 추출 → [번역 JSON] → AI 번역 → 수정 → [빌드 도구] → [한글 패치]
↕ ↕
사람이 교열 ScummVM 엔진 패치때문에 단순히 추출해서 번역하는데에 그치지 않고, ScummVM 의 Kyra 엔진을 수정해서 한글이 나올수 있도록 코드를 개선해야 하는 부분이 포함되었다.
1-3. 두개의 Repo
| 레포 | 역할 | 상태 |
|---|---|---|
| colus001/kyra-2-korean-patch | 번역 데이터 + Python 빌드 도구 | private → 현재 공개 전환 |
| scummvm/scummvm PR #7335 | ScummVM 엔진 C++ 패치 (한국어 렌더링·로딩) | 메인테이너 리뷰 및 머지 대기 중 |
colus001/kyra-2-korean-patch 에 실제 한글화 번역 부분이 존재하고, 이 번역 부분은 OTHER.PAK 라는 단일 파일과 더 디그 에서 가져온 폰트를 파싱해서 만든 ENGLISH.FNT 와 KOREAN.FNT 두 폰트를 기존 게임에 덮어씌우면 한글화된 게임을 만들 수 있다.
ScummVM 은 현재 PR이 리뷰중으로 곧 머지될 것으로 예상한다. ScummVM 에서 처리한 부분은 한글화 된 게임을 detect 하는 코드와, 폰트 로딩, 게임 intro 에 나오는 영문을 한글화 하여 euc-kr 로 인코딩(!)한 코드가 들어있다. 따라서 둘 모두 가지고 있어야 한글화된 키란디아의 전설 2를 플레이할 수 있다.
구글 드라이브에서 모두 다운로드 가능
2부. AI 번역 - 4,448개 문장을 어떻게 번역했나
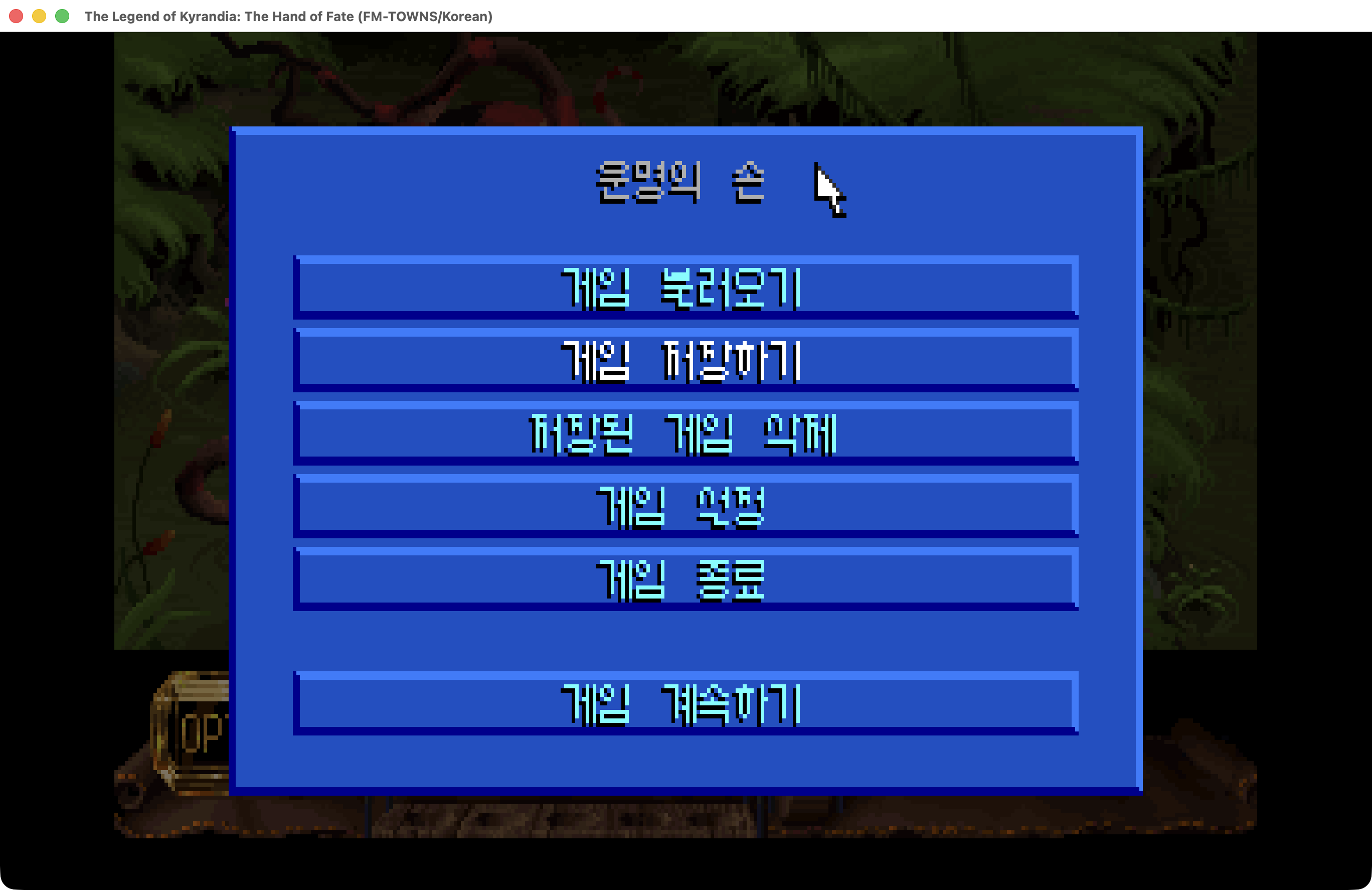
2-1. 번역 대상 분석
| 항목 | 수량 | 예시 |
|---|---|---|
| EMC 스크립트 (인게임 대사) | 2,207개 (153 파일) | "Nice try, but I'm no fool!" |
| DLG 대화 | 1,853개 (40 파일) | NPC와의 대화 선택지 |
| 스트링 테이블 (UI/아이템) | 372개 | "Firefly Tree" → "반딧불 나무" |
| 편지 + 책 페이지 | 16개 | 운명의 수레바퀴 편지 |
| 합계 | 약 4,448개 |
Claude Sonnet 4.6 이 4,448개의 문장을 번역하는데 10분 정도 걸린거 같다. 일단 한글이 나오게 하는데 집중하느라 번역을 감수하진 못했지만, 적당히 잘 된 것 같다. 반말/존대말은 워낙 좀 까다롭긴 해서 전체 플레이를 해보지 않고서는 제대로 검수가 안될거 같긴 하다.
2-2. AI 번역 워크플로우
원본 게임의 PAK 파일들을 풀면 40여개의 .DLG 파일이 추출되는데
[헤더 8바이트]
uint16_le × 4 (csEntry, vocH, scIndex1, scIndex2)
[오프셋 테이블]
uint16_le[] 각 대화 스트림의 바이트 오프셋
[커맨드 스트림들]
cmd 10 → END
cmd 4 → CHANGE_INDEX + 새 인덱스
cmd 11 → ZANTHIA 대사 + 텍스트 길이 + 텍스트 바이트
cmd 12 → ZANTHIA 대사 (talkie, vocLo 포함)
기타 → NPC 대사 (cmd 값 자체가 NPC ID)이 DLG 포멧을 다시 JSON 으로 만들어서 구조를 정리했다.
{
"header": {
"csEntry": 0,
"vocH": 1,
"scIndex1": 7,
"scIndex2": 18
},
"streams": [
{
"stream_index": 0,
"offset": 160,
"entries": [
{
"cmd": "ZANTHIA",
"speaker": "Zanthia",
"text": "I'm on my way to Volcania.",
"text_length": 26
}
]
}
]
}
다시 이 JSON 파일을 번역하기 편리하도록 아래의 JSON 파일의 형태로 만들었다.
[
{
"stream": 0,
"entry": 0,
"speaker": "Zanthia",
"cmd": "ZANTHIA",
"en": "I'm on my way to Volcania.",
"ko": "볼케이니아로 가는 중이야."
}
]빌드시엔 역순으로 하여 최종적으로 다시 OTHER.PAK 파일을 만들게 된다. 이 과정에서 만약 "ko" 에 해당하는 번역이 없으면 영어를 폴백해서 점진적으로 번역이 가능하도록 만들었다.
번역이 너무 길게 되면 문제가 생길수 있고, 게임의 톤을 유지하기 위해 간단한 프롬프트로 (게임의 톤(잔시아의 반말, NPC의 경어), 고유명사 음차 규칙, 줄 길이 제한(20자)) 번역을 진행했다. 번역도 뭔가 직접 하기보다는 게임을 하면서 프롬프트에 룰과 캐릭터들의 관계, 고유명사의 음차 리스트 등을 업데이트 하는게 직접 감수하는 것보다 나을거 같다는 생각이다.
대량 초벌 번역에는 매우 효과적이고, 톤 유지도 잘 되는 듯 하나, 게임의 맥락을 따라잡지 못하거나 언어유희, 말장난 이런 부분들의 번역은 좀 더 프롬프트 개선이 필요하다고 생각한다. 캐릭터별 어투를 미세 조정한다거나 하는 부분은 결국에는 어느정도 사람의 교열이 필요할 거 같다고 생각한다.
3부. 리버스 엔지니어링 - 30년 된 바이너리를 해부하기
3-1. Westwood Studio 의 파일 포멧들
1부에서도 언급했듯이 Westwood 의 게임은 독자적인 포멧을 가지고 있어서 한글화 된 게임들이 아직 많지 않다.
| 포맷 | 용도 | 특징 |
|---|---|---|
| PAK | 아카이브 | 파일명+오프셋 목록, 엔드마커 방식 |
| EMC (Westwood IFF) | 씬 스크립트 | FORM+ORDR+TEXT+DATA 청크 구조 |
| DLG | 대화 | 스트림 기반, talkie/non-talkie 변형 |
| 스트링 테이블 (.ENG) | UI 텍스트 | Bigram + ESC 인코딩 |
각 포맷을 리버스 엔지니어링 해서 Python 도구들을 만들었다. 한글 패치 repo 에 있는 /tools 디렉토리의 Python 도구들을 좀 정리해보면
pak_extract.py/pak_repack.py: PAK 아카이브 열고 닫기emc_tool.py: EMC 스크립트 파싱, TEXT 청크 한글로 교체 → KMC 생성dlg_parser.py: DLG 대화 파싱, EUC-KR로 재빌드 → DLK 생성string_table.py: ENG 스트링 테이블 파싱 → KOR 생성
이 게임에서의 대화는 전부 세 부분에 나뉘어져 있다.
- DLG
일반 대화 스크립트로 주로 게임에서 대사로 보면 된다 - EMC
한 씬에서 일어나는 액션으로 엮여있는 대사로 클릭때마다 랜덤하게 나오는 경우가 많다. - ENG
게임의 UI, 장면의 이름 등이 들어있다.
3-2. EMC -> KMC: 스크립트 패칭의 핵심
EMC 파일의 Westwood IFF 구조는 다음과 같이 생겻다.
FORM [4] + size [4] + "EMC2" [4]
ORDR chunk: 함수 오프셋 테이블
TEXT chunk: 문자열 오프셋 + null-terminated strings ← 여기를 교체!
DATA chunk: 바이트코드 (불변)TEXT 청크만 한국어로 갈아끼우면 되지만, Westwood 구현이 좀 잘못된 점이 있어서 꽤 고생했다. (자세한 건 5-3 에서...)
원본 FERRY.EMC 한국어 FERRY.KMC
┌──────────────┐ ┌──────────────┐
│ FORM "EMC2" │ │ FORM "EMC2" │
├──────────────┤ ├──────────────┤
│ ORDR (동일) │ ─── 그대로 ──→ │ ORDR (동일) │
├──────────────┤ ├──────────────┤
│ TEXT (영어) │ ─── 교체 ───→ │ TEXT (한국어) │
│ [0] "Nice tr │ │ [0] "잘 해봤지 │
│ [1] "Thank y │ │ [1] "고맙긴 한 │
│ [7] "BREUTH. │ │ [7] "BREUTH. │ ← WSA 파일명은 그대로!
├──────────────┤ ├──────────────┤
│ DATA (동일) │ ─── 그대로 ──→ │ DATA (동일) │
│ (바이트코드) │ │ (바이트코드) │
└──────────────┘ └──────────────┘이런식으로 패치된 KMC 가 생성된다.
// scene_hof.cpp
filename = sceneName + ".KMC"; // OTHER.PAK에서 찾음
if (!_res->exists(filename.c_str()))
filename = sceneName + ".EMC"; // HOFCH_1.PAK에서 찾음
이 패치된 EMC 파일은 .KMC 확장자로 저장해서 OTHER.PAK에 집어넣는다. 원본 챕터 PAK 파일(HOFCH_1.PAK 등) 안의 .EMC는 그대로 두고, ScummVM이 OTHER.PAK에서 .KMC를 먼저 찾도록 scene_hof.cpp를 수정했기 때문에 OTHER.PAK 하나만 교체하면 한글화가 된다.
위에서 언급한 DLG (DLK) 나 ENG (KOR) 도 동일한 형태로 봐도 되나, 단순 텍스트 번역에 그치는 것과 다르게 EMC는 게임 로직(바이트코드)이 텍스트를 인덱스로 참조하는 구조라, 텍스트만 따로 빼서 새 파일로 만들 수가 없다. 원본 파일에서 텍스트 영역만 교체하고 오프셋을 재계산해서 다시 조립해야 한다.
3-3. 빌드 파이프라인
이렇게 한글화가 된build_korean.py 다음의 7가지 단계로 실행된다.
ENG스트링 테이블 → JSON 번역 → .KOR (6개)DLG대화 → JSON 번역 → .DLK (40개)ENG편지 텍스트 → 번역 → .KOR (4개)ENG책 페이지 텍스트 → 번역 → .KOR (12개)EMC스크립트 + 번역 JSON → .KMC (133개)- 폰트 복사 (KOREAN.FNT + ENGLISH.FNT)
- 전부 합쳐서 → OTHER.PAK
외부 패키지 의존성 없이 그냥 $ python tools/build_korean.py 한줄이면 전부 빌드되서 FM-Towns 와 DOS CD 의 두 플랫폼으로 동시에 빌드에서 .zip 파일로 만들어준다. 유저는 그냥 해당 게임 폴더에 복붙하면 끝!
4부. 폰트 - 한글 없는 한글화

4-1. 폰트는 어디서 구했나?
한글 폰트가 포함되어있지 않기 때문에 대체할 것을 찾아야 했다. 예전에 The Dig 한국어판(!)에 있는 비트맵 폰트를 재활용하려고 받아둔 게 있어서 이걸 쓰면 될 것 같았다.
KOREAN.FNT: EUC-KR 2,350자, 10×9pxENGLISH.FNT: ASCII 256자, 8×8px → 8×9px로 패딩
한글과 라인 높이를 맞추기 위해서 영문 폰트는 패딩을 하나 줬다.
The Dig 폰트 원본 구조:
[헤더 4바이트]
version(1) + padding(1) + width(1) + height(1)
[글리프 데이터]
1bpp 비트맵, MSB-first, 글리프당 ceil(width/8) × height 바이트
font_converter.py 에서 DIG 폰트의 헤더 4바이트를 떼는 것이 전부이고 이렇게 되면 raw glyph data 가 된다. 이는 ScummVM Kyra 엔진에 이미 중국어 번체 팬 변역을 위한 ChineseFont 클래시를 활용하기 위해서 였다. ScummVM의 ChineseFont::load()가 헤더 없는 raw 데이터를 쓰기 때문이다.
4-2. ScummVM에 한글 폰트 렌더러 추가
중국어 팬 번역을 위한 폰트 시스템에는 비트맵 로딩, 1bpp 렌더링, 외곽선 처리, 1바이트+2바이트 합체(MultiSubsetFont)까지 전부 갖춰져 있었다.
ChineseFont (추상 기본 클래스)
├── 비트맵 로딩: load() — 파일 전체를 raw 바이트로 읽기
├── 렌더링: drawChar() — 1bpp 비트맵을 픽셀로 찍기, 외곽선 지원
└── 글리프 찾기: getFontOffset() — 문자 코드 → 바이트 오프셋 (순수 가상)심지어 키란디아 1에는 이미 한국어 조합형 폰트(JohabFontLoK)가 구현되어 있어서, fetchChar()의 2바이트 읽기 로직에 kJohab 타입까지 준비되어 있었다. 한국어 HOF 폰트가 실제로 새로 작성한 코드는 getFontOffset() 하나 — EUC-KR의 바이트 쌍을 글리프 인덱스로 변환하는 계산식뿐이다. 나머지는 전부 상속받아 썼다.
uint32 KoreanTwoByteFontHOF::getFontOffset(uint16 c) const {
uint8 high = c & 0xFF; // 첫째 바이트: 0xB0~0xC8
uint8 low = (c >> 8) & 0xFF; // 둘째 바이트: 0xA1~0xFE
uint32 index = (high - 0xB0) * 94 + (low - 0xA1);
return index * 18; // 글리프당 18바이트 (10×9px, 2bytes/row)
}
예: "가" = 0xB0A1 → (0xB0 - 0xB0) × 94 + (0xA1 - 0xA1) = 인덱스 0 → 오프셋 0 예: "힣" = 0xC8FE→ (0xC8 - 0xB0) × 94 + (0xFE - 0xA1) = 인덱스 2,349 → 오프셋 42,282
게임 엔진은 폰트 슬롯 하나(FID_KOREAN_FNT)에서 영문과 한글을 모두 그려야 하는데 MultiSubsetFont가 이걸 해결한다.
FID_KOREAN_FNT (MultiSubsetFont)
├── [0] KoreanOneByteFontHOF ← ENGLISH.FNT에서 로드
└── [1] KoreanTwoByteFontHOF ← KOREAN.FNT에서 로드문자가 들어오면
'A' (0x41) → 최상위 비트 0 → [0]번 서브셋(영문)이 처리
'가' (0xB0A1) → 최상위 비트 1 → [1]번 서브셋(한글)이 처리이 MultiSubsetFont도 중국어 번역을 위해 이미 존재하던 클래스라 한국어는 그냥 가져다 썼다. 엔진이 문자열을 한 글자씩 읽을 때, 이 바이트가 1바이트 문자(ASCII)인지 2바이트 문자(한글)인지 판단하는 fetchChar() 함수도 이미 있었는데,
uint16 Screen::fetchChar(const char *&s) const {
uint16 ch = (uint8)*s++;
// kBIG5(중국어)와 kJohab(한국어) 모두 같은 로직
if ((fontType == Font::kBIG5 || fontType == Font::kJohab) && ch < 0x80)
return ch; // ASCII → 1바이트
ch |= (uint8)(*s++) << 8; // 그 외 → 2바이트로 읽기
return ch;
}
kJohab이라는 타입은 키란디아 1의 한국어 지원(JohabFontLoK)을 위해 이미 정의되어있었다. 어떻게 보면 기존 키란디아의 전설1 한글판의 폰트를 가져다 쓰면될거 같긴 한데, 요건 나중에 해봐야겠다.
원래 FM-Towns 버젼에 일본어 번역이 있어서 그걸 기반으로 작업했는데 실제로는 중국어 팬번역의 도움을 많이 받았다.
5부. 버그와의 전쟁 - "가가가가가"
5-1. 버그 #1: 모든 대사가 "가가가가" 로 출력
원인 A — 줄바꿈이 한글을 쪼갠다
HoF 엔진의 preprocessString()은 긴 대사를 화면 폭에 맞게 줄바꿈하는 함수이다. 문제는 이 함수가 ASCII 8px 폰트(FID_8_FNT)로 텍스트 폭을 계산한다는 점.
// text_hof.cpp — 원본 코드 (한국어 수정 전)
Screen::FontId curFont = _screen->setFont(Screen::FID_8_FNT); // ← ASCII 폰트로 전환!
int textWidth = _screen->getTextWidth(p);
// ... 폭이 넘으면 중간에 \r 삽입
int count = getCharLength(p, textWidth / 2);
dropCRIntoString(p, count); // ← 여기서 \r 삽입
ASCII 폰트는 1바이트 = 1글자로 계산하는데 EUC-KR "가"는 0xB0 0xA1 2바이트다. ASCII 폰트 입장에서는 이게 글자 2개로 보이니까, 2바이트 한가운데에 줄바꿈(\r)을 삽입하게 된다.
원본: [0xB0][0xA1][0xB3][0xAA]...
─가── ─나──
\r 삽입: [0xB0][\r][0xA1][0xB3][0xAA]...
??? 줄바꿈 ??? ???
2바이트 시퀀스가 깨지면 0xA1이 다음 바이트와 엉뚱하게 결합되고, 결국 전체 문자열이 깨져서 "가"의 글리프(인덱스 0)가 반복 출력된다.
수정: 한국어일 때 HoF 오버라이드를 건너뛰고, 2바이트 문자를 올바르게 처리하는 기본 클래스로 위임:
// 수정 후 — 5줄로 해결
if (_vm->gameFlags().lang == Common::KO_KOR)
return TextDisplayer::preprocessString(_talkBuffer);
원인 B — 일본어 스크립트를 한글 폰트로 읽는다
씬 스크립트 로딩 코드에 이런 줄이 있었다.
// scene_hof.cpp — 원본 코드 (한국어 수정 전)
int scriptLangIdx = (_flags.platform == Common::kPlatformDOS && !_flags.isTalkie)
? 0 : _lang; // _lang=5(한국어)가 그대로 배열 인덱스로!
filename = sceneName + "." + _scriptLangExt[scriptLangIdx];
_scriptLangExt 배열:
[0] "EMC" (영어)
[1] "FMC" (프랑스어)
[2] "GMC" (독일어)
[3] "JMC" (일본어) ← _lang=5일 때 범위 초과로 여기에 접근
한국어의 _lang=5는 이 배열의 범위(0~3)를 벗어난다. 운이 좋으면 크래시, 운이 나쁘면 인덱스 3(일본어)으로 매핑되어 .JMC 파일을 로드한다. Shift-JIS로 인코딩된 일본어 텍스트가 EUC-KR 폰트로 렌더링되면 → 전부 깨진 글리프 → "가가가가" 로 표시되게 된다.
수정: 한국어는 별도 분기로 .KMC를 직접 로드:
if (_flags.lang == Common::KO_KOR) {
filename = sceneName + ".KMC";
if (!_res->exists(filename.c_str()))
filename = sceneName + ".EMC";
}
왜 디버깅이 힘들었나
두 버그 모두 증상이 "가가가가"로 동일하고, 원인 A를 고쳐도 원인 B가 남아있으니 여전히 "가가가가". 원인 B를 먼저 고쳐도 원인 A가 남아있으니 여전히 "가가가가". 한쪽을 고쳤는데 증상이 안 바뀌면 "내가 잘못 고친 건가?" 하고 의심하게 되고, 둘 다 동시에 고쳐야 처음으로 정상적인 한글이 보이게 된다.

이 두 문제에 동시에 "가" 에러가 난 이유는 getFontOffset() 에서 찾을수 없으면 0 을 리턴하기 때문이었음.
5-2. 버그 #2: "Game data not found"
증상 - 게임을 처음 실행하면 정상 동작. 두 번째 실행부터 ScummVM이 "Game data not found" 에러를 뿜으며 게임을 인식하지 못한다.
원인 - ScummVM은 게임 종료 시 writeSettings()에서 현재 언어를 설정 파일에 저장하게 된다.
# ScummVM 설정 파일
[kyra2-ko]
gameid=kyrandia2
language=ko ← writeSettings()가 저장한 값
다음 실행 시 ScummVM은 이 language=ko를 가지고 detection 테이블에서 매칭되는 엔트리를 찾는데 detection 엔트리는 EN_ANY로 등록되어 있으니 → 매칭 실패되어 정상적으로 실행아 안된다.
해법의 진화 (3단계)
1단계 — 순진한 구현: language=ko 저장 → 버그 발생
2단계 — 워크어라운드: fan translation이면 무조건 language=en 저장
// 동작은 하지만... 설정 파일에 "en"이라고 적힌 게 찜찜
if (_flags.fanLang != Common::UNK_LANG)
ConfMan.set("language", "en");
3단계 — 근본 해결 (PR 최종): detection 엔트리 자체를 KO_KOR로 등록하고 KOREAN.FNT를 detection 키로 사용
// detection_tables.h — KOREAN.FNT의 MD5와 크기로 한국어판 구별
AD_ENTRY2s("FATE.PAK", "28cbad...", AD_NO_SIZE,
"KOREAN.FNT", "6b32a...", 42300),
Common::KO_KOR, // detection 언어 자체가 KO_KOR
이제 language=ko 가 올바른 값이 된다.
if (_flags.fanLang == Common::KO_KOR)
ConfMan.set("language", Common::getLanguageCode(Common::KO_KOR));왜?
ScummVM은 게임 시작 시 detection 엔트리의 lang 값으로 kyra.dat에서 해당 언어 리소스를 로드한다. 그래서 만약 lang = KO_KOR로 설정하면,
시작 → lang=KO_KOR → kyra.dat에서 KO_KOR 리소스 찾기 → 없음 → 실패
그래서 fan translation 메커니즘이 이중 언어 설정을 사용한다.
lang = EN_ANY ← kyra.dat 로딩용 (영어 리소스 가져오기)
fanLang = KO_KOR ← 실제 게임 내 언어 (한국어 파일 확장자, 폰트 등)
엔진 시작 순서
1. lang=EN_ANY로 kyra.dat에서 영어 리소스 로드 ← 성공
2. _flags.lang = KO_KOR로 전환 ← 이제부터 한국어 모드
3. .KOR, .DLK, .KMC, KOREAN.FNT 로드
kyra_hof.cpp에서 실제로 이 전환을 한다.
// kyra.dat 로딩이 끝난 후 한국어로 전환
if (_flags.fanLang == Common::KO_KOR)
_flags.lang = Common::KO_KOR;
5-3. 버그 #3: Chunk overread (3부에서 언급한 form_size)
증상 - KMC 파일을 로드하면 ScummVM IFFParser가 "Chunk overread" 에러 발생한다.
원인 - IFF 표준대로 form_size = file_size - 8로 설정했는데, Westwood 원본 EMC는 비표준인 form_size = file_size 으로 저장하고 있었다. ScummVM의 IFFParser가 Westwood 방식 기준으로 파싱하므로, 표준값을 넣으면 8바이트 차이로 오프셋이 안 맞게 된다.
# emc_tool.py — 수정 전
form_size = file_size - 8 # IFF 표준 → Chunk overread 에러
# 수정 후
form_size = file_size # Westwood 방식 → 정상 동작
8바이트 차이 하나가 파일 전체를 못 읽게 만드는 케이스...

6부. ScummVM 에 기여하기
6-1. ScummVM Fan Translation 메커니즘
위에서도 언급한 것과 같이 팬 번역은 기본적으로 ScummVM 이 공식적으로 지원하는 프레임워크로, 이번 한글화 또한 중국어 팬 번역을 활용해서 시간을 많이 절약할 수 있었다.
FLAGS_FAN(KO_KOR, EN_ANY)
// ~~~~~~~~ ~~~~~~
// fanLang replacedLang(base)
이 한 줄이 하는 일
gameFlags().lang = EN_ANY→ kyra.dat에서 영어 리소스 로드gameFlags().fanLang = KO_KOR→ 런타임에서 한국어 분기 활성화gameFlags().replacedLang = EN_ANY→ 원래 언어가 뭐였는지 기억
엔진 시작 후 kyra_hof.cpp에서 전환하여 실제 한국어 모드를 지원하고 번역을 파일을 불러온다.
if (_flags.fanLang == Common::KO_KOR)
_flags.lang = Common::KO_KOR; // 이제부터 한국어 모드
파일 확장자 체계 — 언어마다 다른 확장자
ScummVM Kyra 엔진은 언어별로 같은 이름, 다른 확장자의 파일을 찾는다.
| 파일 종류 | 영어 | 프랑스어 | 독일어 | 일본어 | 한국어 |
|---|---|---|---|---|---|
| 스트링 테이블 | .ENG |
.FRE |
.GER |
.JPN |
.KOR |
| 대화 | .DLG |
.DLF |
.DLE* |
.DLJ |
.DLK |
| 씬 스크립트 | .EMC |
.FMC |
.GMC |
.JMC |
.KMC |
* DOS CD에서는 영어가 .DLE, 독일어가 .DLG
이것 때문에 또 해프닝이 있었는데, FM Towns 를 기반으로 작업해서 잘 되는지라 별 문제가 없다고 생각했는데, 갑자기 번역 안된 텍스트에서 독일어가 갑자기 튀어나왔다. 워낙 오래된 게임이지만, 이런 부분에서 일관성이 부족하다니 너무 한거 아니냐고.

staticres.cpp에 한국어 확장자를 등록하면 엔진이 _lang 값에 따라 자동으로 골라 읽게 된다.
const char *const KyraEngine_HoF::_languageExtension[] = {
"ENG", "FRE", "GER", "JPN", "POL", "KOR" // ← [5]번에 추가
};
폴백 구조 — 번역이 없어도 게임은 돌아간다
KMC(한국어 스크립트)는 133개인데, 원본 EMC는 137개인데, 이런 경우에는 번역 안 된 4개 씬은 영어 EMC로 자동 폴백되도록 하였다.
filename = sceneName + ".KMC";
if (!_res->exists(filename.c_str()))
filename = sceneName + ".EMC"; // 없으면 영어로
DLK, KOR도 마찬가지로, 번역을 50%만 해도 게임은 돌아간다. 번역된 부분은 한국어로, 안 된 부분은 영어로 나오게 되는데, 이 구조 덕분에 번역을 점진적으로 진행하면서 중간중간 게임을 실행해 확인할 수 있었다. FM-Towns 버젼과 DOS 버젼의 텍스트가 미묘하게 달랐기 때문에 종종 문제가 생겼었다.
6-2. ScummVM 공식 레포에 기여하기
| 항목 | 수치 |
|---|---|
| 변경 파일 | 15개 (engines/kyra/ 하위) |
| 추가 | +357줄 |
| 삭제 | -28줄 |
| 최종 커밋 | 1개 (squash) |
15개 파일이 하는 일을 네 가지로 분류하면,
게임 인식 (detection)
detection_tables.h — KOREAN.FNT의 MD5로 한국어판 구별
devtools/create_kyradat/* — kyra.dat에 한국어 엔트리 추가
폰트 렌더링
screen.h — KoreanOneByteFontHOF, KoreanTwoByteFontHOF 클래스
screen.cpp — MultiSubsetFont으로 ENGLISH.FNT + KOREAN.FNT 합체
screen_hof.cpp — EUC-KR 글리프 오프셋 계산, 색상 매핑
파일 로딩
scene_hof.cpp — .KMC 우선 로드 + .EMC 폴백
text_hof.cpp — .DLK 접미사, preprocessString 위임
staticres.cpp — .KOR 확장자 등록, kyra.dat 리소스 머지
kyra_v2.cpp — _lang=5 매핑
엔진 통합
kyra_hof.cpp — 언어 전환, 폰트 로딩, writeSettings, bigram 스킵
gui_hof.cpp — 메뉴에 "한국어" 표시, 언어 순환 잠금
sequences_hof.cpp — 인트로/타이틀 한글 폰트
까다로운 리뷰가 있을걸 걱정했는데, 코드 자체에 대한 수정 요청은 없었고, 커밋 형태만 맞춰달라는 거였어서 squash 해서 하나의 commit 으로 정리해서 올렸다.
머지되면 어떻게 되나
현재는 ScummVM 과 한글 패치를 둘 다 배포하고 있는데, 빨리 머지되어서 공식 ScummVM 으로도 한글 패치한 게임을 편하게 실행할 수 있게 되면 좋을 것 같다.
사용자는 패치된 ScummVM을 별도로 받을 필요 없이,
- 공식 ScummVM + 한글 패치 파일만 있으면 되고,
- ScummVM이 게임 폴더를 스캔할 때
KOREAN.FNT를 발견하면 자동으로 Kyrandia 2 (Korean)으로 인식된다.
Kyra 엔진을 쓰는 게임이 많지는 않지만 주시자의 눈이나 랜드 오브 로어 도 이 엔진을 썼다고 하니까, 다음에 한글화할 누군가에게 도움이 되면 좋겠다.
7부. AI 의 가능성
마치 내가 한 것처럼 썼지만, 실은 이 모든걸 OpenCode 와 Antrophic 의 Opus 와 Sonnet 로 만들어 낸 것이다.

그럼 나는 뭘 했나?
나
| 역할 | 구체적으로 |
|---|---|
| 재료 확보 | The Dig 한국어판에서 폰트 파일 확보, Kyrandia 2 원본 게임 파일 확보 |
| 방향 제시 | "The Dig 폰트를 써라", "ScummVM 엔진을 이렇게 패치해라", "이 바이너리 포맷은 이런 구조다" |
| 디버깅 | 직접 게임 실행 → "가가가가 나온다", "두 번째 실행하면 안 된다", "독일어가 나온다" → 증상 리포트 |
| 품질 관리 | 번역 교열, 화면에서 잘리는지 확인, 게임 진행하면서 맥락 검증 |
| Git/PR 관리 | 커밋, 롤백, force-push, 메인테이너와 소통 |
OpenCode
| 역할 | 구체적으로 |
|---|---|
| 코드 작성 | Python 빌드 도구 10개, ScummVM C++ 패치 15개 파일 |
| 번역 | 4,448개 문장 초벌 번역 |
| 포맷 분석 | 바이너리 포맷 파싱 로직 구현 |
| 버그 수정 | 리포트된 증상을 기반으로 원인 추적 + 코드 수정 |
| 문서 작성 | README, TECHNICAL, CONTRIBUTING 등 |
어떤 느낌이냐면 이 한글화 프로젝트의 리더가 된 기분이었다. 약 40 시간 정도 작업을 한거 같은데, 생각보다는 손이 많이 가긴 했지만 (테스트와 디버깅은 내 몫이었으니) 직접 하려는 엄두 조차 나지 않았는데, 수월하게 진행되었다.
예전부터 작업을 하려고 재료는 다 모아논 상태였는데, 지나고 나니 충분히 나 혼자서도 할만 했겠었지만, 이 작업을 하려면 어디 부터 수정해야 할지도 감이 오지 않았을거다. Python 과 C++ 코드를 거의 한줄도 직접 쓰지 않고 작업했고, 번역 감수도 많이 하지 않았으니 내가 했다는 느낌은 거의 없지만, 이게 바로 AI 와 함께 일하는 엔지니어링(?)이 아닌가 싶다.
덕분에 AI 에 대한 약간 회의에서 긍정적인 측면으로 돌아온 것 같다. 혼자 했다면 번역만 해도 상당히 힘들었을텐데 이 모든걸 거의 4일만에 다 했으니 말이다. 새로운 시대가 오는건 확실한 것 같고, 이제 적응할 때가 된 것 같다.